bean的创建过程及循环依赖的解决方式
这篇文章主要讲 Spring bean 的创建过程,以及 Spring 为什么要用三级缓存来解决循环依赖的。原本是打算写 Spring 的启动过程,边读边写,断断续续快半年,内容实在太多,于是打算拆成若干个文章,此是第一篇基础。
首先奉上bean创建过程的大流程图,文章结尾还有循环依赖的另一个流程图。
三级缓存和其它较重要的变量
首先我们有个基本概念,Spring 使用三级缓存来创建 bean、解决循环依赖,三级缓存其实就是三个 Map。
| 缓存 | 说明 |
|---|---|
| 一级 | 用于存放可以使用的成品bean |
| 二级 | 用于存放半成品bean,这些bean仅仅刚被创建,没有进行填充属性和实例化,用于解决循环依赖 |
| 三级 | 存放bean工厂对象,用于生产半成品的bean并放入第二级缓存,用于解决循环依赖 |
这些变量都在 DefaultSingletonBeanRegistry类下,还有其他变量,如用于标记哪些 bean 正在创建中的集合。
在这还有个 registerDependentBean 方法,很多地方出现了,这里也只是拎出来,这篇文章不需特别关注。
1 | // 在 类下 |
代码块0 创建bean的大入口
1 | protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType, |
代码块1 解决循环依赖的核心
从三个缓存中寻找 bean,一级缓存找不到,就去二级找,二级也找不到就去三级找。入参 allowEarlyReference 用于决定是否允许在第三级缓存中寻找。
1 | public Object getSingleton(String beanName) { |
代码块2 创建bean前后的一些操作
主要有以下流程:
- 如果一级缓存里有bean,直接返回。
- 未创建,标记此bean在创建中。
- 创建 bean。
- 标记bean创建完成。
- 将bean添加到一级缓存中。
1 | public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) { |
代码块3 将bean添加到一级缓存
这是将 bean 添加到一级缓存,同时移除二三级缓存,逻辑很简单。
1 | protected void addSingleton(String beanName, Object singletonObject) { |
代码块4 在创建bean之前尝试走代理
创建 bean ,包含两部分
- 在创建bean之前,给一个代理的机会,有代理对象就直接返回
- 没有代理,走真正创建bean的流程
1 | protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) |
1 | // 在实例化之前解决 |
代码块5 创建bean的实际过程
主要三个步骤:
- 实例化
- 填充属性
- 初始化 (Aop等)
1 | protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args) |
这就是上面说的骚操作,在正常流程中替换一个 bean,请不要这样做。
1 | @Component |
代码块6 添加到三级缓存
将bean添加到三级缓存中,添加的是该bean的ObjectFactory,一个工厂
1 | protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) { |
此方法是 ObjectFactory 的具体内容,就是找到所有的 SmartInstantiationAwareBeanPostProcessor 并执行其 getEarlyBeanReference 方法
1 | protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { |
其中最重要的 SmartInstantiationAwareBeanPostProcessor 是 AbstractAutoProxyCreator,用于处理代理的,其方法如下:
1 | public Object getEarlyBeanReference(Object bean, String beanName) { |
代码块7 初始化bean
1 | protected Object initializeBean(final String beanName, final Object bean, @Nullable RootBeanDefinition mbd) { |
初始化 bean 的代码
1 | protected void invokeInitMethods(String beanName, final Object bean, @Nullable RootBeanDefinition mbd) |
上面提到了 AbstractAutoProxyCreator 类的 getEarlyBeanReference 方法,里面调用了 wrapIfNecessary 方法,这个类也实现了初始化之后的钩子,用于aop代理。虽然有多个地方尝试进行包装代理,但实际上一个对象只能被代理一次,要不然会出现多个实例了,毕竟每次执行代理都产生一个新的对象。
1 | public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) { |
到这里, bean 的创建过程基本就结束了。我们再用一个例子来加深理解,下图是 Chicken 和 Egg 相互循环依赖的时的创建过程, Chicken 需要被代理, Egg 无所谓是否需要代理,流程都是这样:
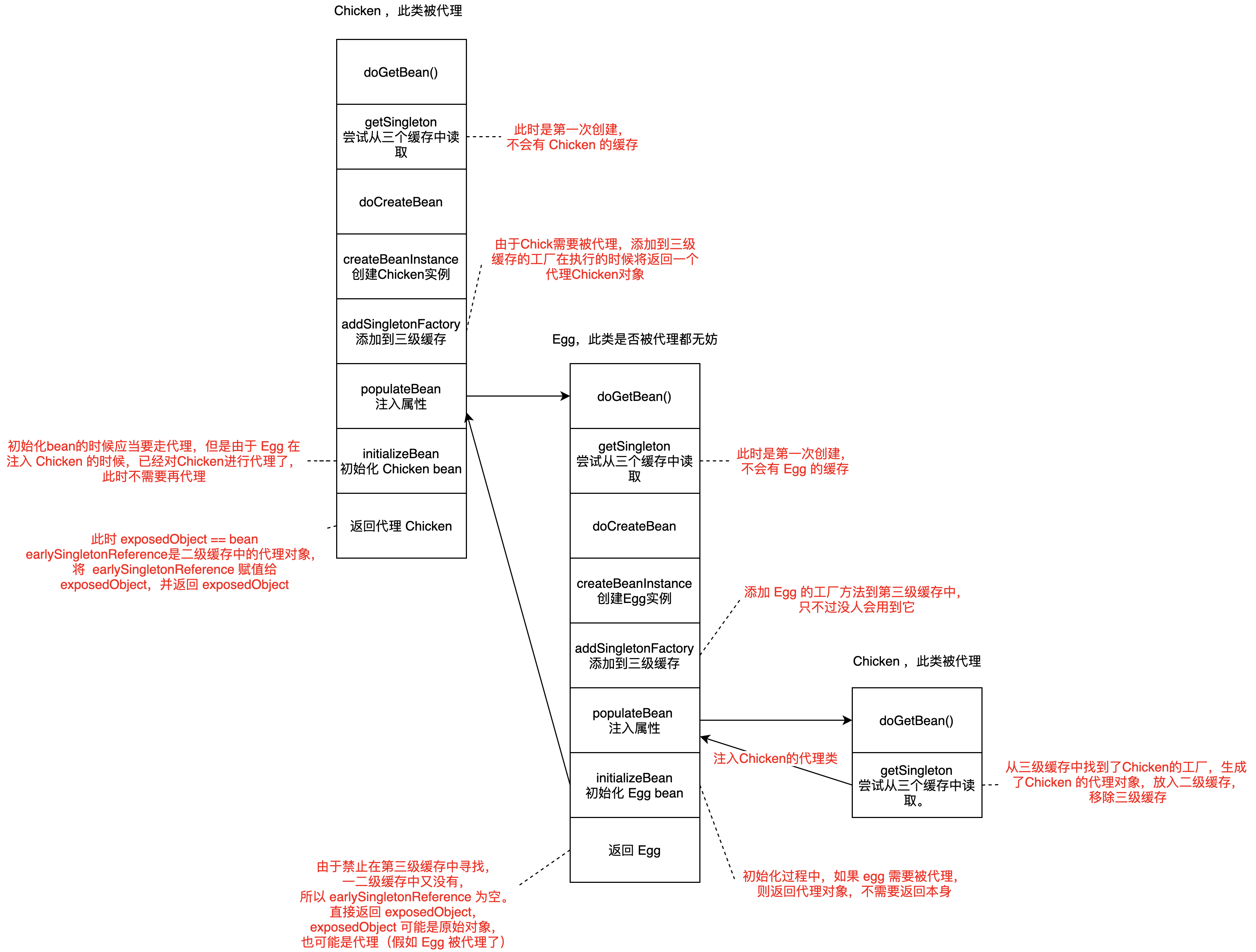
为什么需要三级缓存?
如果只用二级缓存可以吗,会有什么问题呢?也是可以的,解决循环依赖有两种选择:
- 不管有没有依赖,实例化后都立刻创建好代理对象,并将半成品对象放入缓存,出现循环依赖时,其他对象直接取出代理对象注入即可。这种只需要二级缓存即可。
- 不提前创建代理对象,在出现循环引用,被其它对象注入的时,才生产代理对象。如果没有出现循环引用,就按 Spring 的设计原则走。
Spring采用的是第二种选择, Spring 的设计原则是如果没有循环依赖,通过 AnnotationAwareAspectJAutoProxyCreator 这个初始化后置处理器来在 bean 生命周期的最后一步来完成 Aop 代理,而不是实例化之后立刻进行 Aop 代理。如果出现循环依赖,要想不在实例化之后立刻 Aop 代理,只能引入第三级工厂缓存,在其他 bean 在注入自己的时候,执行 getEarlyBeanReference ,进行代理,然后注入。
但是,由于在 getBean 的时候,它也不知道有没有循环依赖,于是所有 bean 的都先将 getEarlyBeanReference 工厂添加到三级缓存中,只不过没有循环依赖的时候,完全不会用到第三级缓存罢了,有循环依赖,就执行,放入二级缓存。
参考:
面试必杀技,讲一讲Spring中的循环依赖
曹工说Spring Boot源码(29)– Spring 解决循环依赖为什么使用三级缓存,而不是二级缓存
Spring循环依赖三级缓存是否可以减少为二级缓存?