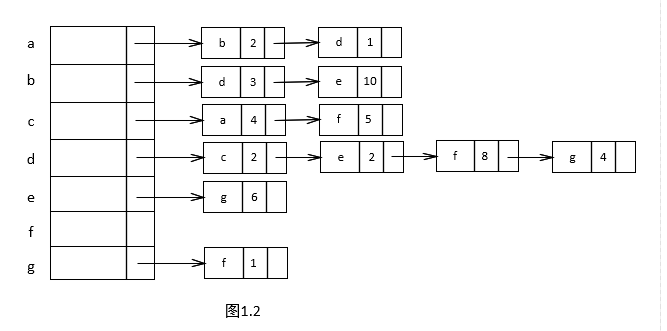
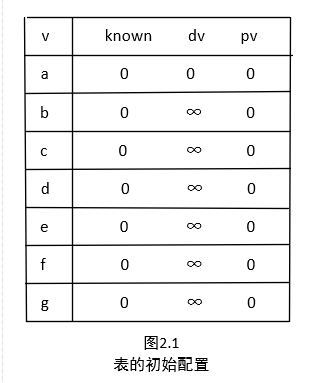
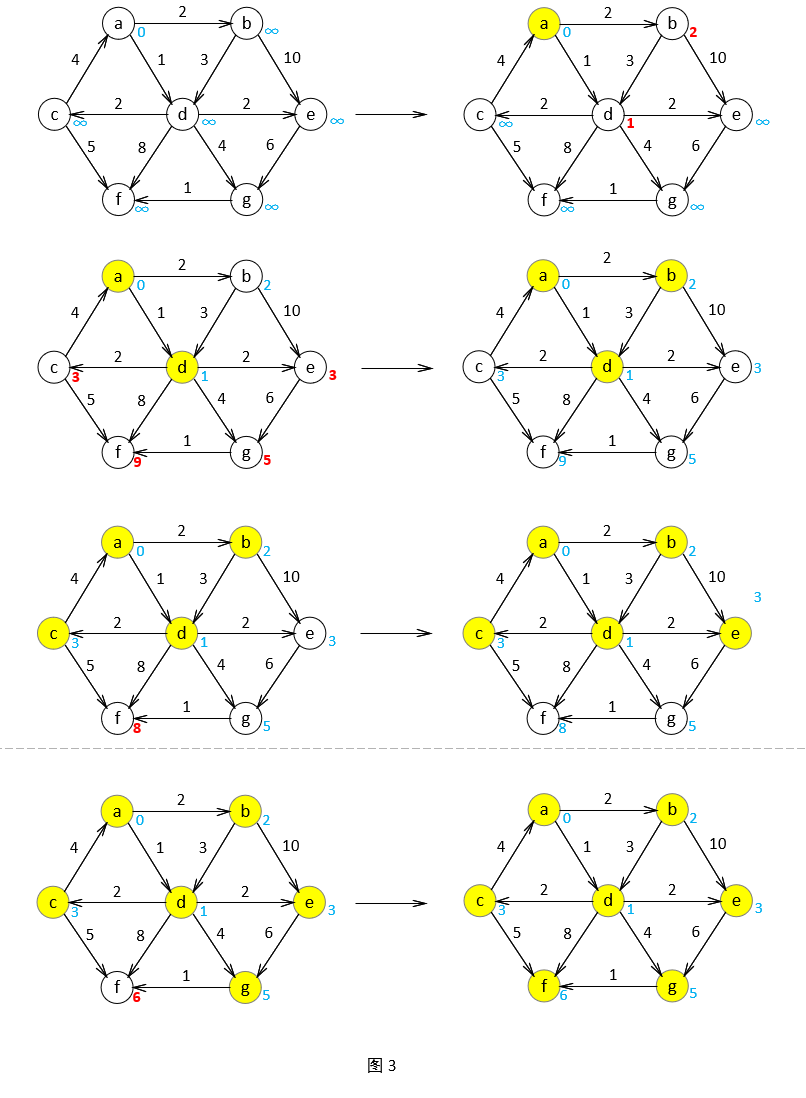
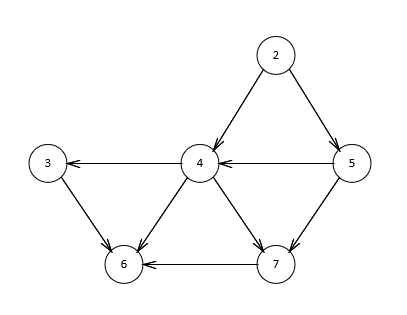
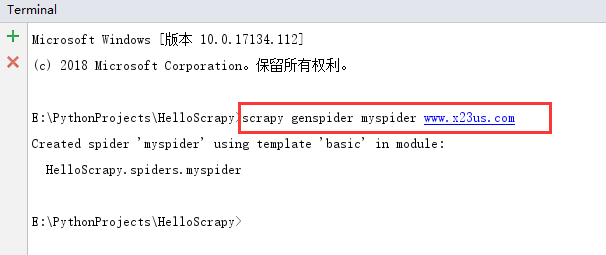
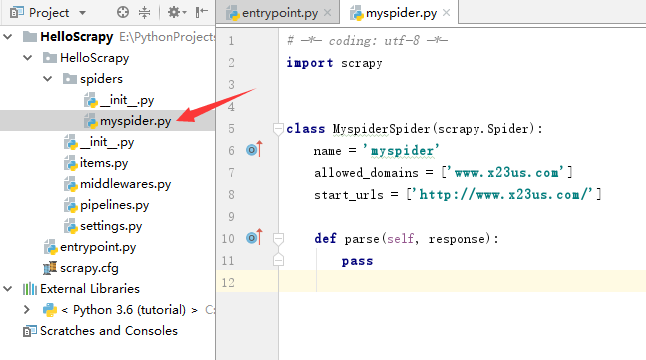
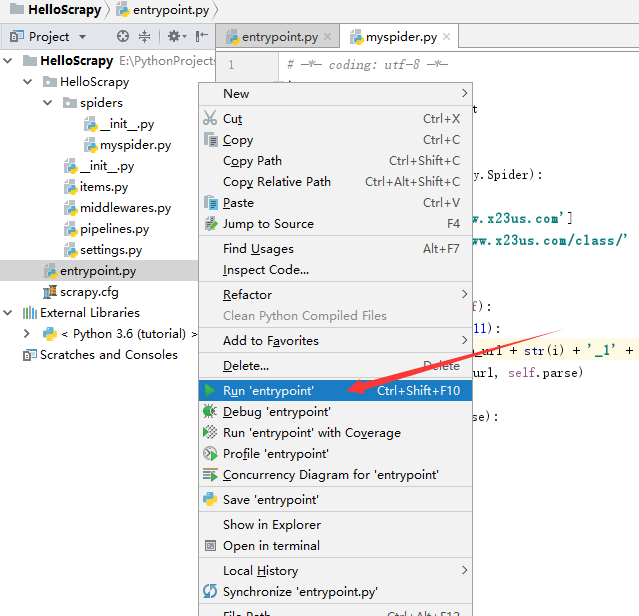
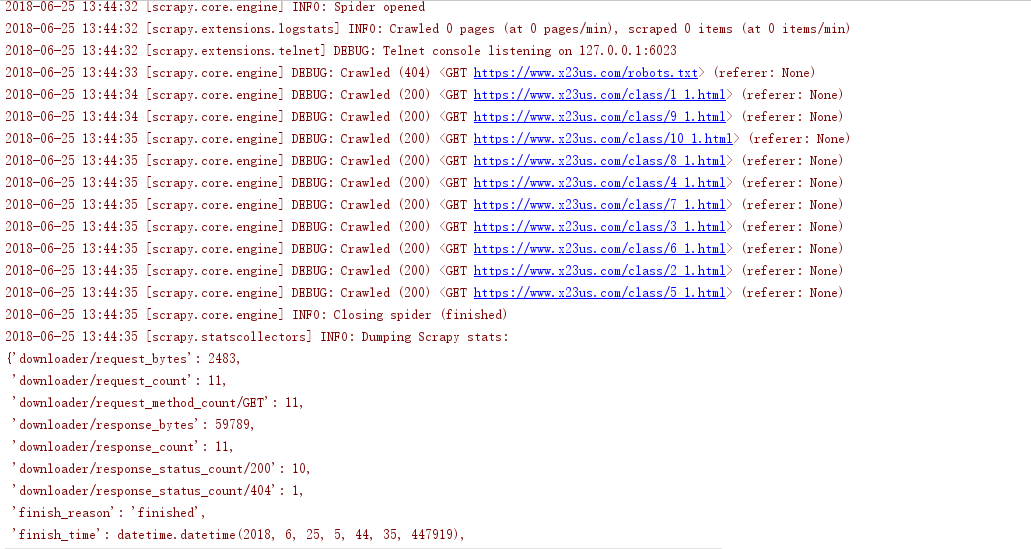
首先,我们需要对每个顶点进行标记,每个顶点标记为Known(已知)的,或者标记为unKnown(未知的)。同时,每个顶点需要保留一个临时距离 dv 。这个距离实际上是使用已知顶点作为中间顶点从开始顶点 s 到 v 的最短路径的长。最后,我们记录 pv ,它是引起 dv 变化的最后的一个顶点。假如开始顶点 s 是 a ,那么用于Dijkstra算法的表的初始配置应当如图2.1所示。
Dijkstra算法按阶段进行,在每个阶段,Dijkstra算法选择一个顶点 v ,它在所有未知顶点中具有最小的dv,同时算法声明从 s 到 v 的最短路径是已知的。阶段的其余部分由dw值的更新工作组成。
图2.1表示我们初始配置,且开始节点为 s 为 a。
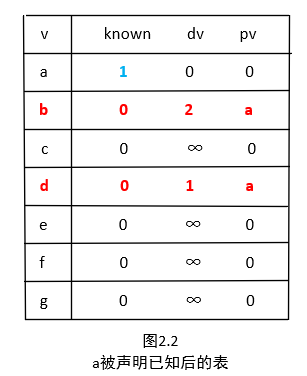
第一个选择的顶点是 a ,因为它在所有未知的顶点中具有最小的 dv ,dv 为0。将 a 标记为已知。既然 a 已知,那么某些表项就需要调整。观察图1.1,发现邻接到 a 的顶点有 b 和 d 。那么这两个顶点的项需要调整,调整后如图2.2所示。
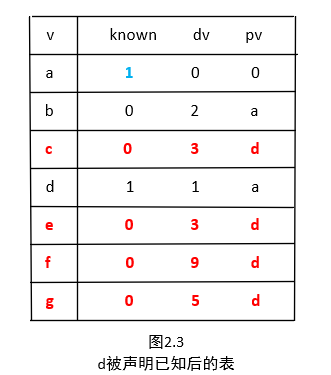
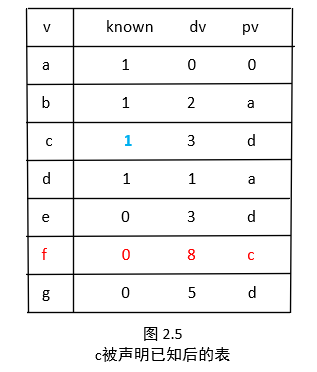
继续选择一个未知的且具有最小 dv 的顶点,也就是 d ,顶点 c,e,f,g 是邻接的顶点,而且它们实际上都需要调整,如图2.3所示。
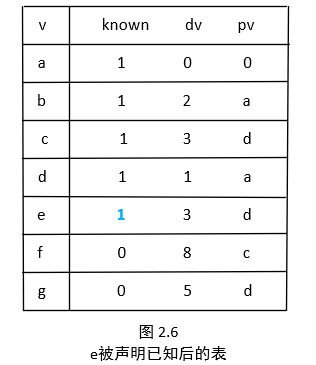
下一个被选取的顶点是 b ,其值为 2。d 是邻接的点,但已经是已知的,因此不必做对其做工作了。 e 也是邻接的点但不需要调整,因为结果 b 的值为 2+10=12。大于 e 已知的长度为3的路径。图 2.4指出这些顶点被选取以后的表。
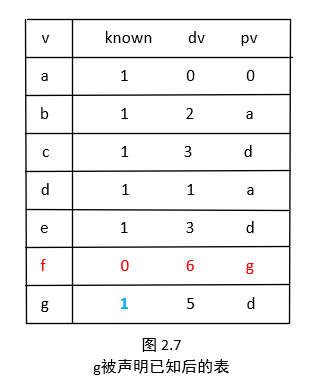
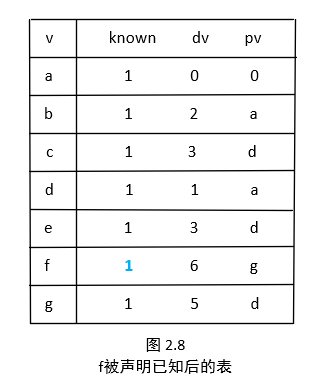
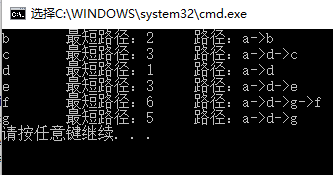
在算法结束后,我们最终得到了一张表(图 2.8)。在这张表里面,我们可以得到我们想得到的一切。例如 a 到 f 的最短路径为6。那么如何得到 a 到 f 的实际路径呢?我们可以编写一个递归来跟踪 pv 留下的痕迹。引起 f 的 dv 变化的最后的一个顶点是 g ,那么查询 g ;引起 g 的 dv 变化的最后的一个顶点是 d ,继续查 d ;引起 d 的 dv 变化的最后的一个顶点是 a ,也就是我们的开始节点,不需要继续查了, a 到 f 的最短路径就是 a->d->g->f 。
while (!zeroInDegreeQueue.isEmpty()) { IntegernowVisit= zeroInDegreeQueue.poll(); List<Integer> tos = adjacencyMatrix.get(nowVisit); for (Integer to : tos) { if (--indeg[to] == 0) { zeroInDegreeQueue.add(to); } } }
void createHeapTop2Buttom(int arr[], int len) { for (int i = 1; i < len; i++) { int c = i; int p = (c - 1) / 2; //i父亲的下标 while (arr[p] < arr[c]) { //如果父亲比此节点小,则更换 int tmp = arr[p]; arr[p] = arr[c]; arr[c] = tmp; //将当前节点更新为父节点继续调整 c = p; p = (c - 1) / 2; } //满足大根堆,直接调整完毕 } }
自下到上构造大根堆, 时间复杂度为O(n)
void createHeapButtom2Top(int arr[], int len) { for (int p = len / 2 - 1; p >= 0; p--) { //int p = p; int maxid = p; while (1) { //有孩子节点比父节点大 if (p * 2 + 1 < len &&arr[maxid] < arr[p * 2 + 1]) { maxid = p * 2 + 1; } if(p * 2 + 2 < len && arr[maxid] < arr[p * 2 + 2]) { maxid = p * 2 + 2; } if (p == maxid) { break; } int tmp = arr[maxid]; arr[maxid] = arr[p]; arr[p] = tmp; p = maxid; } } }
堆排序
void heapSort(int arr[], int len) { while (len > 1) { createHeapButtom2Top(arr, len); int tmp = arr[0]; arr[0] = arr[len - 1]; arr[len - 1] = tmp; len--; } }
在数据通信中,需要将传送的文字转换成二进制的字符串,用0,1码的不同排列来表示字符。例如,需传送的报文为“AFTER DATA EAR ARE ART AREA”,这里用到的字符集为“A,E,R,T,F,D”,各字母出现的次数为{8,4,5,3,1,1}。现要求为这些字母设计编码。要区别6个字母,最简单的二进制编码方式是等长编码,固定采用3位二进制,可分别用000、001、010、011、100、101对“A,E,R,T,F,D”进行编码发送,当对方接收报文时再按照三位一分进行译码。显然编码的长度取决报文中不同字符的个数。若报文中可能出现26个不同字符,则固定编码长度为5。然而,传送报文时总是希望总长度尽可能短。在实际应用中,各个字符的出现频度或使用次数是不相同的,如A、B、C的使用频率远远高于X、Y、Z,自然会想到设计编码时,让使用频率高的用短码,使用频率低的用长码,以优化整个报文编码。
wget https://twistedmatrix.com/Releases/Twisted/17.1/Twisted-17.1.0.tar.bz2 tar -jxvf Twisted-17.1.0.tar.bz2 cd Twisted-17.1.0 python3 setup.py install
解压可能会遇到如下错误
tar (child): lbzip2: Cannot exec: No such file or directory tar (child): Error is not recoverable: exiting now tar: Child returned status 2 tar: Error is not recoverable: exiting now