Scrapy 爬虫入门实战
最近两天又闲得慌了,学习了一下爬虫。爬虫,久闻大名,如雷贯耳,总觉得是个很牛逼的东西,难度不小。学了两天下来,发现是很牛逼,但是难度真的不大。
在学习之前,一片空白。大约一年前看过廖雪峰的Python教程,现在估计也忘得差不多,如果你也是Python小白的话,去看下廖雪峰的Python教程吧。花了小半天时间复习了一下Python,这门语言入门还是很简单的,如果有其它语言的基础,大约一个小时就能写点东西出来了。
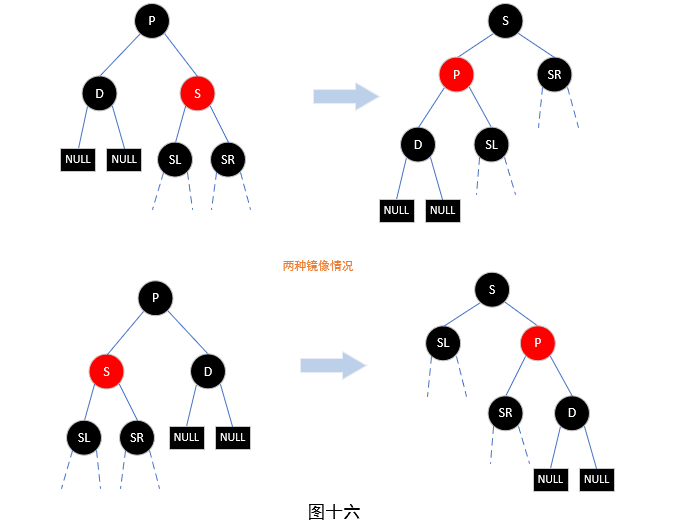
那么我们再去查Python环境下如何实现爬虫,发现一个特别特别强大的框架——scrapy,那我们就用它了。嗯?网上不是说有很多东西么?urllib、urllib2、bs4、pyspider、beautifulsoup什么什么的?一张图你就懂了

先了解下爬虫的原理。
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
爬虫是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么爬虫就可以用这个原理把互联网上所有的网页都抓取下来。
废话不多说,我们直接开工,首先装环境,我装的Python3.6版本,win10系统。Python安装完成之后,前往pip的官网https://pip.pypa.io/en/stable/installing/,安装pip,提供了一个get-pip.py文件,下载之后运行即可。
_pip_是一个现代的,通用的 Python 包管理工具。提供了对 Python 包的查找、下载、安装、卸载的功能。
打开cmd,输入 pip -V ,检查pip版本,没有问题后开始安装scrapy,指令为 pip install scrapy ,安装完成之后,cmd输入 scrapy version,可以查看版本号,我使用的是1.5。
之后我们还要用到mysql,这里也顺便把包安装好,指令为 pip install pymysql。
现在我们需要创建一个scrapy的工程,在自己想建立工程的位置运行cmd,输入 scrapy startproject HelloScrapy, HelloScrapy是我们的工程名。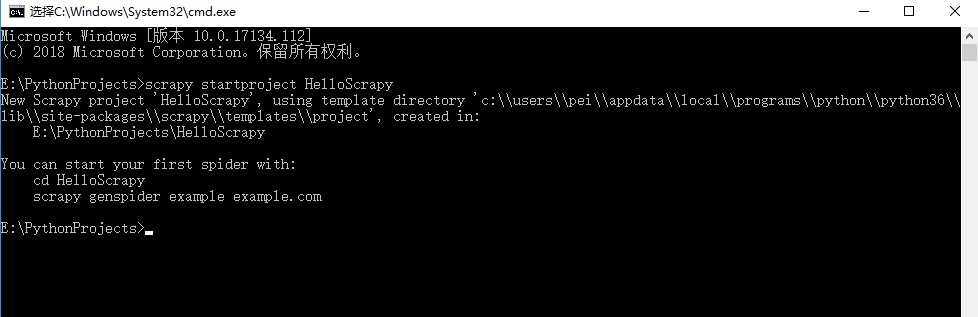
接下来,我们用PyCharm,打开我们创建的这个工程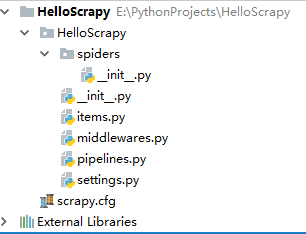
查看目录结构,scrapy为我们生成了很多东西,spiders文件夹下放的是我们写的爬虫代码,items.py是用来定义我们所需要获取的字段piplines.py是用来定义我们的存储,settings.py是定义的各种设置。现在不懂没关系,反正我们之后会用到,写一写就明白了。
现在,我们要做一件事,在根目录里,新建一个entrypoint.py文件,里面输入以下代码
1 | from scrapy.cmdline import execute |
因为Scrapy默认是不能在IDE中调试的,以后我们直接运行这个py文件就可以跑整个项目。
现在我们的项目应该是这样的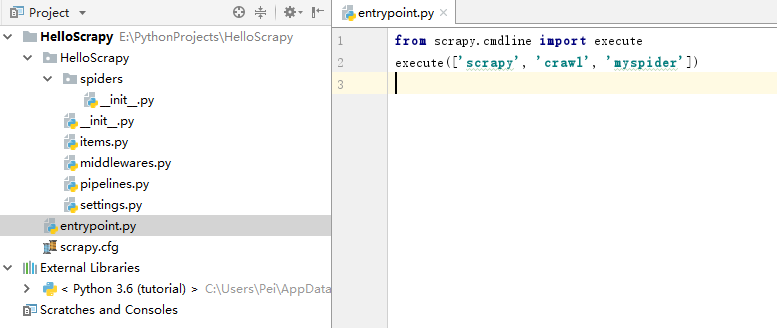
第二行中代码中的前两个参数是不变的,第三个参数是自己的spider的名字。
可是,我哪里来的myspider…别急,我们现在就来建立。首先,我们先找个爬取的目标——顶点小说,(对不住了) 现在的域名是www.x23us.com(此网站域名经常变化,谷歌搜顶点小说就好) ,那么我们在IDE里面打开terminal 输入 scrapy genspider myspider www.x23us.com 回车之后,scrapy就会用模板给我们自动生成一个爬虫
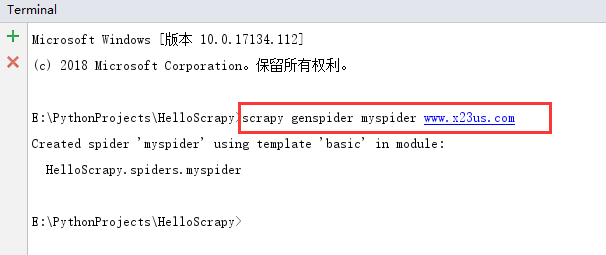
查看项目结构,多了一个文件,还有一些代码。
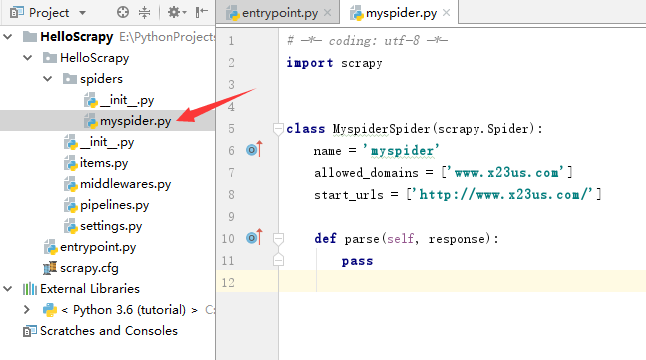
其中,name这个字段就是我们的spider的名字,整个项目不可重复。
allowed_domains这个字段是用来过滤爬取的域名,如果一不小心爬到别的地方了,就可以通过这个字段过滤掉。
start_urls就是我们第一个爬取的起始地址,这是一个list,所以可以起始地址可以有很多个。
还有一个parse方法,每个网页请求成功之后,都会调用这个方法进行处理。
爬取一个网站,肯定要先分析它是如何组成的 。
打开首页,有很多分类,自己一个个点开会发现url后缀的变化,2_1.html,3_1.html,4_1.html等等。那么爬虫的入口地址就有了
玄幻魔幻:http://www.x23us.com/class/1_1.html
武侠修真:http://www.x23us.com/class/2_1.html
都市言情:http://www.xx23us.com/class/3_1.html
历史军事:http://www.x23us.com/class/4_1.html
侦探推理:http://www.x23us.com/class/5_1.html
网游动漫:http://www.x23us.com/class/6_1.html
科幻小说:http://www.x23us.com/class/7_1.html
恐怖灵异:http://www.23wx.com/class/8_1.html
散文诗词:http://www.23wx.com/class/9_1.html
其他:http://www.23wx.com/class/10_1.html
入口有两种写法,一种是用start_urls变量,直接把上述的url地址放进去,但是不太美观。还有一种是重写start_requests函数,重写这个函数之后,start_urls就不起作用了,我使用的后者,将地址拼接出来了。
现在运行entrypoint.py
可以看见控制台输出了一大堆日志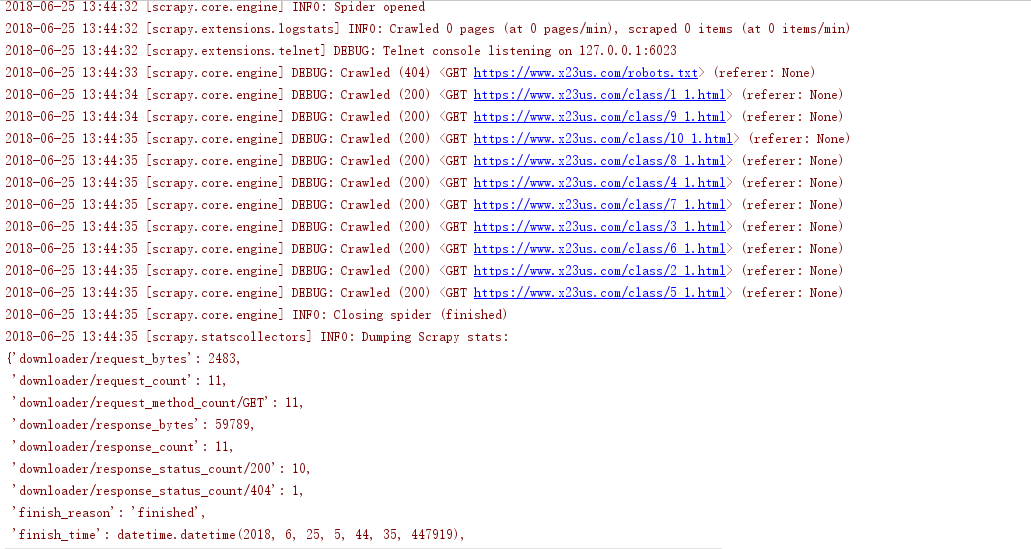
看见这些,就说明OK了。
现在我们要遍历所有的页面来获取所有小说
每个分类下面可以看到总页数,我们获取每个分类的总页数,然后循环,理论上就可以拿到所有页面了。如何获得这个总页数?这就需要用到xpath,找到这个元素在html的位置。不知道什么是xpath?没关系,多用用就明白了,没什么复杂的(其实我也不懂啥事xpath - -!)。我使用的谷歌浏览器,右键单击上图中的106
点击最下面的检查
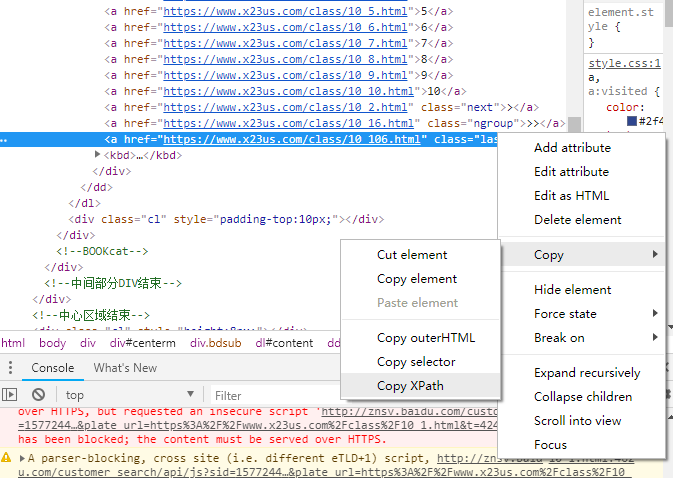
右键单击蓝色高亮的代码,Copy -> Copy XPath 就能拿到位置,复制到的是
1 | //*[@id="pagelink"]/a[14] |
想要拿到它里面的值需要这样
1 | response.xpath("//*[@id='pagelink']/a[14]/text()").extract_first() |
/text()能够获得里面的值,response.xpath() 返回的是一个list,使用,如果列表里只有一个元素,使用extract_first()来提取,如果list里面有多个元素,就必须要使用extract()来获取全部元素。

我们构造完URL之后继续调用Reques,回调函数为parse_name()

我们要拿到每一个小说的名称和作者,和拿到最大值的流程一样,懒癌犯了,直接贴代码…..
分别获得三个列表,然后for循环一个个取出来,发现多了一个meta字典,这是Scrapy中传递额外数据的方法,因我们还有一些其他内容需要在下一个页面中才能获取到。
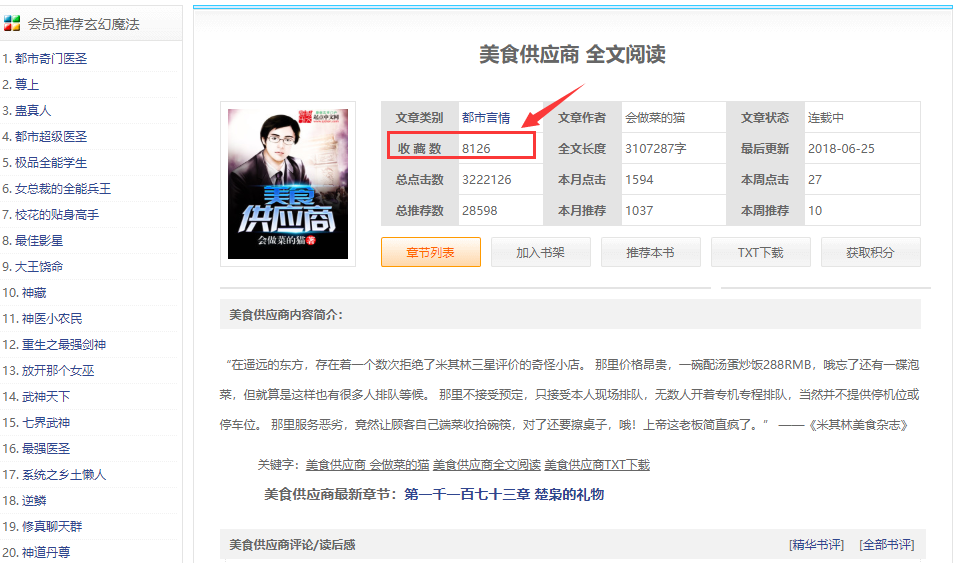
现在我们的爬虫到了这个页面,这个页面我们就取一个收藏数吧
1 | collect_num_str=response.xpath('//*[@id="at"]/tr[2]/td[1]/text()').extract_first() # 网页中含有<span style="color: inherit; font-size: inherit;"> 空格 ==> \xa0</span>``collect_num=int("".join(collect_num_str.split())) #去掉空格的编码 收藏数 |
pre宋体';font-size:10.5pt;"这里有个要注意的地方,网页中含有 ,我们提取出来的/pre宋体';font-size:10.5pt;"collect_num_str含有\xa0,我们需要去掉它。

至今为止我们,已经抓取了我们想要的内容了,小说名称,作者,链接,收藏数。上面的代码都打印出来了。
现在我们需要存到数据库里面。这时候我们需要编辑item.py了

写下这四个我们所需的字段。
在根目录下新建mysqlpiplines文件夹,文件夹下面建立sql.py。
我们要在sql.py里面编写我们的sql语句。打码的四个变量写上你自己的。
主要写了两个方法,一个插入,一个根据小说名称判断是否已经存在。
现在编辑piplines.py
接着我们修改一下我们的爬虫代码。
把我们拿到的数据传给item,剩下的就不需要我们做了。
最后一步,打开settings.py,关掉ITEM_PIPELINES的注释
这个300是优先级,现在不需要管它,关闭掉注释就可以了。
我们跑下项目,爬虫已经可以开始正常工作
大约爬了三十分钟,抓起了三万八千多条记录。是不是特别强大?